您的购物车目前是空的!
分类: 文章分类
-
智能手表缺了“AI大脑”,你的手表就过时了?
每天早上醒来,先瞥一眼智能手表——睡眠得分、心率、日程提醒……你有没有想过,这些习以为常的功能背后,其实藏着三类不同的AI“大脑”:分析式AI、生成式AI和智能体AI。
这三类AI各司其职,有的帮你“读数据”,有的帮你“造内容”,有的帮你“办事情”。智能手表里藏着“AI大脑”,你的智能手表用了哪类AI?
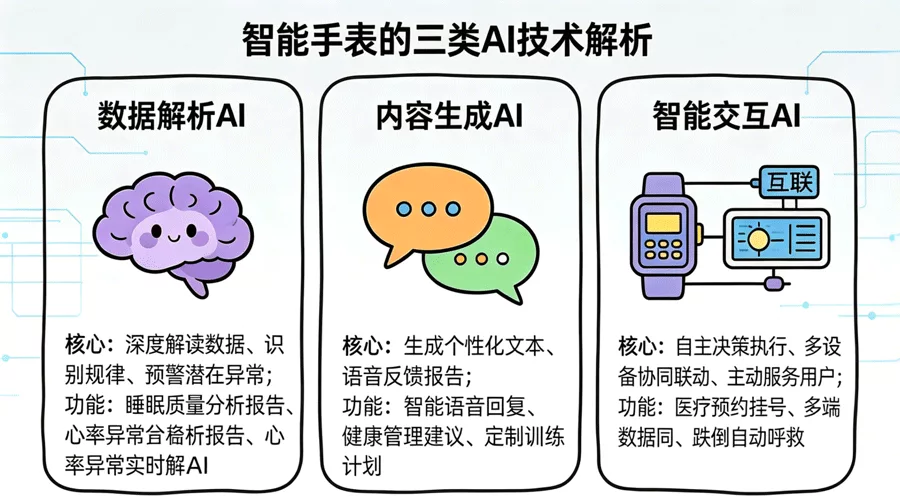
ai大脑 分析式AI:手表的“基础核心”,90%的手表都有!
分析式AI是智能手表的看家本领。它不创造新内容,只专注“读数据、找问题”。无论百元手环还是千元手表,核心的健康监测和运动分析,基本靠它。
典型场景:
- 戴表睡觉,早上看到“深睡2小时、浅睡4小时、清醒10分钟”——这是分析式AI解读体动和心率,划分睡眠周期;
- 跑步时显示“步频180、配速5分30秒”,跑完提示“步幅偏大,调整避免膝盖损伤”——这是它结合历史数据和健康阈值,给出风险提醒;
- 心慌时手表震动“心率持续120+,请休息”——这是它实时监测心率,识别异常并预警。
简单说,没有分析式AI,手表就是个“电子表+计步器”,连基本健康监测都做不到。
生成式AI:让手表“会说话、会创作”,体验更贴心
分析式AI是“读数据”,生成式AI则是“把数据变生动”——它能根据需求生成文本、语音、报告等新内容,让手表不再是冷冰冰的数据屏。
这类功能越来越常见,尤其在中高端手表上:
- 对着手表说“帮我回复消息,说我半小时后到”,手表自动生成语音或文字回复——这是生成式AI理解指令后创作回复内容;
- 每周收到“健康周报”,文字总结“本周睡眠良好,深睡平均2.5小时,建议周末适度运动”——这是它整合一周数据生成的个性化报告;
- 设定“减脂目标”后,手表自动生成每日训练计划,包含动作和时长——这是它根据健康数据与目标定制的方案。
生成式AI的核心价值是“降低理解成本”——不用自己看枯燥的原始数据,手表直接把结论和建议“说给你听、写给你看”。
智能体AI:手表的“终极形态”,能自主办事的管家
智能体AI不仅能“读数据、造内容”,还能“自主决策、主动办事”,甚至跨设备联动,解决实际问题。目前主要出现在高端手表或搭载大模型的新款上。
几个“黑科技”场景:
- 监测到血压连续3天超标,自动预约医院体检号,同步血压数据给医生,并在固定时间提醒服药——这不是预警,而是主动解决健康问题;
- 说一句“我明天出差去上海”,手表自动同步航班、规划路线,联动手机订接机车,提醒带身份证——跨设备协同,一站式搞定;
- 老人不慎跌倒,手表自动识别跌倒状态,无需操作,直接联系紧急联系人、发送定位,并播报急救指南——主动救援,关键时刻救命。
智能体AI的核心是“主动服务”——不用你逐一下指令,它能根据数据和习惯预判需求并完成任务。

你的手表用了哪类AI?
大多数手表并非只用某一类,而是“组合拳”:
- 入门手环:以分析式AI为主——计步、睡眠、心率,偶尔带点基础生成式AI(简单语音回复);
- 中端手表:分析式AI+生成式AI——完整健康监测、个性化报告、语音交互;
- 高端/新款手表:三合一——主动健康管理、跨设备联动、自主办事。
比如早上醒来,手表显示睡眠报告(分析式AI),语音播报“今日睡眠85分,早餐建议多吃蛋白质”(生成式AI),同时提醒“明天上午9点体检,已同步至手机日历”(智能体AI)——这就是三类AI协同工作的典型场景。
分析式AI负责数据解读与预警,生成式AI优化交互体验与内容输出,智能体AI主导主动服务与问题解决。随着技术发展,越来越多手表将搭载三类AI,从“工具”进化为真正的“随身伙伴”。
-
小狮AI智能耳机:以AI+声学双核心,重塑蓝牙耳机
深耕海外蓝牙耳机市场多年,来自深圳小狮智能有限公司的“小狮AI”凭借硬核品质赢得全球用户口碑,斩获高销量与好口碑,成功跻身全球智能耳机实力派阵营。企业长期专注声学研发与人工智能革新,始终以用户体验为核心,精雕细琢每一款产品。如今,小狮AI重磅推出搭载全新蓝牙6.0协议的AI智能蓝牙耳机,集高颜值设计、卓越音质、顶级降噪、AI黑科技于一身,以全方位硬核实力颠覆大众对无线耳机的传统认知。
一、核心突破:AI智能终端,重构耳机使用场景
小狮AI耳机的核心竞争力在于其持续迭代的全维度AI智能黑科技。它已从单一音频播放设备升级为集实时翻译、语音转写、智能交互、健康管理于一体的智能终端,可接入豆包、文心一言、DeepSeek等大模型,并具备会议纪要自动生成、AI通话降噪与自适应音频调校等能力。
- 智能交互与语音控制:支持AI语音问答、智能对话、语音控制、智能通话等功能。用户无需手动操作,仅通过语音指令即可发起通话、拨打联系人、切换音乐、调节设备状态,解放双手、便捷高效。
- 实时翻译与会议辅助:内置AI智能翻译功能,支持双向同传、同声传译、视频通话实时翻译及AI总结提炼。同时具备录音转写、语音速记转文本、实时提词等功能,特别适合商务会议、跨境沟通、境外出行等场景。
- 健康管理与场景感知:部分高端产品集成心率、血氧监测、耳机掉落检测、颈椎疲劳提醒等功能,应用场景持续向运动健康、智能家居控制、车载系统联动、学习辅助、情感陪伴等领域延伸。
二、精工品质与佩戴体验:人体工学设计 + 智慧屏显
小狮AI始终坚守精工品质,从外观设计到内部结构,每一处细节都经过千锤百炼。
- 佩戴设计:采用人体工学原创设计,贴合国人及全球用户耳型轮廓,实现稳固贴耳的佩戴效果。部分型号采用耳夹式开放设计、零压钛芯记忆合金骨架、不入耳结构,并应用银离子抗菌涂层,久戴不压耳、运动不脱落。
- 智慧屏显:机身做工精细,搭配五款高颜值动态屏显及全彩AMOLED智慧触摸显示屏。轻点屏幕即可切换模式、调节音量、查看状态,打破传统耳机的单一操作局限,颜值与实用性双向拉满。
三、极致音质:专业声学 + 高清解码 + 空间音频
音质是耳机的灵魂,小狮AI耳机在此实现了极致突破。
- 声学结构:搭载专业声学结构腔体(如ACAVITY腔体)、SSQVP EXTREME数字声音增强技术及声波聚焦技术,有效减少漏音。
- 音效与解码:加持HIFI高保真音质、ACS全景音效与影院级IMAX环绕音,支持LDAC、LHDC 5.0、aptX Lossless等高清音频解码,获得Hi-Res金标认证。同时集成DTS空间音效、THX空间音效、杜比音效并支持头部追踪空间音频技术,营造立体开阔的声场。
- 个性化调节:配备三大调音模式、七种均衡音色调节,适配流行、古典、摇滚等各类曲风。结合定向传音技术,精准聚焦声源,有效避免漏音,独享私密听觉空间。
四、顶级降噪:ANC主动降噪 + ENC通话降噪
降噪能力直接决定使用体验。小狮AI搭载双重核心降噪技术:
- ANC主动降噪:可深度屏蔽通勤车流、商场人声、办公室嘈杂等环境噪音,一键开启静谧模式。
- ENC双麦/四麦克风通话降噪:结合波束成形技术,精准过滤通话背景杂音,清晰收录人声。无论是户外通话、线上会议还是直播沟通,都能实现超清无损通话。
五、无线连接与续航:蓝牙6.0 + 超长续航
此次升级的蓝牙6.0协议实现了无线传输的跨越式革新:
- 连接性能:抗干扰能力更强、传输速率更快、延迟更低,在密集网络环境下也能保持稳定连接,彻底杜绝听歌卡顿、音画不同步、游戏断连等问题。
- 功耗与续航:大幅降低功耗,搭配整机超长续航配置,日常通勤、长途出行、全天办公无需频繁充电,告别电量焦虑。
六、购买提示:认准官方渠道,拒绝山寨
凭借极致的产品力与扎实的品牌口碑,小狮AI耳机远销海外、火爆热销。市场火爆的同时,山寨高仿产品频发,严重影响使用体验。在此郑重提醒:购买请认准官方正规渠道,可前往小狮官网、小狮AI企业店及各大电商官方旗舰店选购,守护正品品质与售后保障。
七、发展趋势与愿景:从音频工具到可穿戴智能终端
小狮AI耳机已从单纯的“声音传递工具”进化为集语音识别、实时翻译、智能交互、场景感知于一体的“可穿戴智能终端”。“专业声学+AI”的深度耦合成为核心竞争力,AI不断优化声学体验,如通过开放主动降噪、千人千听技术等实现智能化降噪和个性化音质。
展望未来,小狮AI耳机的应用场景正从早期的实时翻译、会议转写,持续向运动健康(心率监测、血氧检测、运动指导)、智能家居控制、车载系统联动、学习辅助、情感陪伴等更广阔领域延伸。其中,针对商务人群的会议纪要、实时提词、即时翻译等场景,被视为具有高替代价值的下一波重要增长点。据中研普华预测,到2030年,TWS耳机有望从音频设备升级为“健康数字终端”,全面整合入智能家居与车载系统。
-
小狮AI耳机凭啥领跑行业创新?小狮持续迭代的AI智能黑科技
深耕海外蓝牙耳机市场多年,凭硬核品质圈粉全球用户,斩获超高销量与口碑——来自深圳小狮智能有限公司的小狮AI,早已跻身全球智能耳机实力派阵营。多年专注声学研发与智能技术革新,不跟风同质化内卷,始终以用户体验为核心,打磨每一款产品,如今重磅推出搭载全新蓝牙6.0协议的AI智能蓝牙耳机,集颜值、音质、降噪、AI黑科技于一身,凭全方位硬核实力,颠覆大众对无线耳机的固有认知。
小狮AI耳机凭啥领跑行业创新?是其持续迭代的全维度AI智能黑科技,小狮AI耳机集成人工智能技术,已从单一音频播放,升级为集实时翻译、语音转写、智能交互及健康管理等于一体的智能终端,应用场景持续向运动健康、智能家居控制、车载系统联动、学习辅助、情感陪伴等领域延伸。小狮品牌深耕AI声学技术多年,不断探索研发AI语音问答、智能对话、语音控制、智能通话等前沿功能,解锁懒人智能新体验。无需手动操作,只需语音指令,即可一键发起通话、拨打指定联系人电话、切换音乐、调节设备状态,解放双手、便捷高效。同时内置AI智能翻译功能,实时精准翻译,跨境沟通、境外出行无障碍,兼具娱乐、办公与实用价值,适配全场景使用需求。
小狮打造“专业声学+AI”的核心竞争力,研发团队一直优化声学音频技术、智能降噪、专用芯片与算法、健康监测、交互方式及佩戴设计,多语言翻译,双向同传,录音转写、同声传译、视频通话实时翻译及AI总结提炼,以及语音速记转文本、智能问答与语言陪伴,可接入豆包、Genmini、ChatGPT、DeepSeek等大模型,并具备会议纪要自动生成、AI通话降噪与自适应音频调校等能力。
支撑AI功能的硬件与软件基础包括集成专用AI神经网络处理器,如6nm 6核AI NPU,并搭载HiFi5 DSP处理器,通过深度优化算法提升语音唤醒灵敏度、翻译准确率可达98%及转写准确率。
深耕行业多年,小狮AI始终坚守精工品质,从外观设计到内部结构,每一处细节都经过千锤百炼。耳机采用人体工学原创设计,贴合国人及全球用户耳型轮廓,实现稳固贴耳的佩戴效果,久戴不压耳、运动不脱落,兼顾舒适感与实用性。机身做工精细、工艺精美,搭配五款高颜值动态屏显,自带全彩智慧触摸显示屏,操作直观便捷,轻点屏幕即可切换模式、调节音量、查看状态,打破传统耳机单一操作局限,颜值与实用性双向拉满。
音质作为耳机的核心灵魂,小狮AI耳机做到了极致突破。小狮耳机搭载专业声学结构腔体,加持HIFI高保真音质、ACS全景音效与影院级IMAX环绕音,层层还原声音细节,高低音通透饱满,声场立体开阔,沉浸式听歌宛如置身现场。同时配备三大调音模式、七种均衡音色调节,可适配流行、古典、摇滚等各类曲风,满足不同用户的听觉偏好。搭配定向传音技术,精准聚焦声源,有效避免漏音、不扰民,独享私密听觉空间,兼顾音质质感与使用私密性。为保障音质与AI交互,采用了专业声学结构如ACAVITY腔体、SSQVP EXTREME数字声音增强技术及声波聚焦技术以减少漏音,并支持LDAC、LHDC 5.0、aptX Lossless等高清音频解码,获得Hi-Res金标认证,同时集成DTS、THX、杜比三大空间音效标准并支持头部追踪空间音频技术。
降噪能力直接决定使用体验,小狮AI搭载双重核心降噪技术,全方位隔绝外界干扰。ANC主动降噪可深度屏蔽通勤车流、商场人声、办公室嘈杂等环境噪音,一键解锁静谧模式;ENC双唛通话降噪精准过滤通话背景杂音,清晰收录人声,无论是户外通话、线上会议还是直播沟通,都能实现超清无损通话,告别杂音困扰。智能降噪与通话方面应用了AI降噪算法、开放主动降噪技术,以及四麦克风ENC通话降噪与波束成形技术以提升通话清晰度。AI优化声学体验,如通过开放主动降噪、千人千听技术等实现智能化降噪和个性化音质。
此次升级的蓝牙6.0协议,更是实现了无线传输的跨越式革新。相比传统蓝牙版本,其抗干扰能力更强、传输速率更快、延迟更低,在密集网络环境下也能保持稳定连接,彻底杜绝听歌卡顿、视频音画不同步、游戏断连等问题,同时大幅降低功耗,搭配整机超长续航配置,日常通勤、长途出行、全天办公无需频繁充电,彻底告别电量焦虑。
凭借极致的产品力与扎实的品牌口碑,小狮AI耳机远销海外、火爆热销,成为全球用户认可的国民级智能耳机品牌。市场火爆的同时,山寨高仿频发,严重影响使用体验。在此郑重提醒大家:购买认准官方正规渠道,可前往小狮官网、小狮AI企业店等各大电商官方旗舰店选购,拒绝三无假货,守护正品品质与售后保障。
以匠心深耕品质,以科技革新体验。小狮AI始终坚守创新初心,用前沿技术、精工工艺、极致体验,重新定义智能蓝牙耳机新标准。这款集蓝牙6.0、AI智能交互、顶级降噪、影院级音质、高颜值设计于一体的全能耳机,无论是日常自用、通勤娱乐、办公学习,还是送礼甄选,都是绝佳选择,解锁全场景智能听觉新体验!
交互方式涵盖智能触控、语音助手唤醒、体感控制,并通过充电仓AMOLED触控彩屏进行可视化操作和内容显示。
佩戴与设计技术包括耳夹式开放设计、零压钛芯记忆合金骨架、不入耳结构,并应用人体工学数据积累、3D打印定制腔体及银离子抗菌涂层等技术以提升佩戴舒适性与声学效果。
小狮耳机从单纯的“声音传递工具”进化为集语音识别、实时翻译、智能交互、场景感知于一体的“可穿戴智能终端”。部分高端产品开始集成心率、血氧监测等健康管理功能,以及耳机掉落检测、颈椎疲劳提醒等场景感知功能。
发展愿景
小狮AI耳机的应用场景正从早期的实时翻译、会议转写,持续向运动健康(如心率监测、血氧检测、运动指导)、智能家居控制、车载系统联动、学习辅助、情感陪伴等更广阔领域延伸。其中,针对商务人群的会议纪要、实时提词、即时翻译等场景,被视为具有高替代价值的下一波重要增长点 。中研普华预测,到2030年,TWS耳机有望从音频设备升级为“健康数字终端”,整合入智能家居与车载系统。
-
小狮品牌蓝牙耳机/智能手表“技术赋能体验,品质铸就口碑”
始于2015,专注AI硬件的创新者
小狮AI,我的AI助手!
小狮品牌诞生于2015年,隶属于深圳超乎科技有限公司,是一家专注于AI智能硬件研发与创新的科技企业。自成立以来,我们始终秉持“让AI技术服务于每个人成长”的使命,致力于将前沿人工智能技术转化为实用、易用的智能硬件产品,让AI创新真正惠及每一个家庭。
我们的产品矩阵:构建全方位AI学习生态
九年来,小狮已建立起完整的AI智能产品线:
- 小狮AI智能手表:不仅仅是时间工具,更是孩子的安全伙伴与健康管家
- 小狮AI手环:轻量化设计,全天候健康监测与学习提醒
- 小狮AI学习机:个性化学习路径规划,智能互动教学体验
- 小狮AI耳机:ANC主动降噪、可触摸显示屏、ENC双唛通话降噪、三大调音模式、定向传音技术、HIFI音质、声学结构腔体、影院级IMAX环绕音、ACS全景音效、全新升级蓝牙6.0、超长续航、定向传声不传音、稳固贴耳
- 小狮AI学习闹钟:有思想、会对话、能规划、全科学习、陪你成长的AI伙伴
每一款产品都承载着我们对“智能教育”的深刻理解——技术不应是冰冷的工具,而应成为温暖、贴心的成长伙伴。
技术核心:深耕多模态大模型AI硬件
领先的AI技术布局
小狮研发团队始终走在AI硬件技术的前沿。我们坚信,真正的智能硬件必须拥有“大脑”。因此,我们大力投入基于多模态大模型的AI硬件研发:
- 自研AI技术架构:专为教育场景优化的硬件计算平台
- 多模态融合技术:低功耗语音、视觉、触觉的多维度交互多模态感知系统
- 边缘计算优化:在本地设备上实现高效AI推理,保护用户隐私
- 自适应学习算法:设备能够随使用时间越长,越懂用户需求
技术创新里程碑
- 2017年:实现蓝牙耳机在ANC+ENC双唛降噪的突破
- 2019年:推出首款搭载语音识别芯片的儿童手表
- 2021年:基于大模型的AI引擎应用正式投入使用
- 2023年:自研多模态交互框架在学习机上成功应用
- 2024年:小狮AI学习闹钟开创“对话式时间管理”新品类
团队基因:技术钻研与持续探索
工程师文化驱动创新
小狮团队由一群热爱技术、相信教育变革的工程师、产品设计师和教育专家组成。我们的研发团队占比超过60%,其中:
- 核心算法团队来自国内外顶尖AI实验室
- 硬件工程师拥有平均10年以上的消费电子研发经验
- 教育内容团队与全国教学名师深度合作
持续探索的研发哲学
我们从不满足于现有技术,而是持续探索AI硬件的可能性:
“三个坚持”研发原则:
- 坚持自主创新:关键核心技术必须掌握在自己手中
- 坚持用户价值:每个技术突破都要转化为实际使用价值
- 坚持长期投入:在基础研究和前沿领域持续布局
品质承诺:严苛标准造就可靠产品
全链条质量控制
从方案探索、芯片选型到最终成品,小狮产品需经过严格测试:
- 72小时连续压力测试
- -10℃至50℃极端温度测试
- 5000次按键耐久性测试
- 儿童安全材料认证
- 3C认证、电信入网许可、无线电发射信号核准
用户隐私保护
我们深知教育数据的重要性,因此:
- 本地化AI处理,敏感数据不出设备
- 获得ISO27001信息安全管理体系认证
- 严格遵守《儿童个人信息网络保护规定》
使命与愿景:用AI点亮成长之路
我们的使命
让每个孩子都能享受到个性化的AI教育,让技术不再是少数人的特权,而是每个家庭触手可及的成长助力。
我们的愿景
成为全球AI教育硬件的引领者,通过持续的技术创新,重新定义学习的方式与体验。
数字见证成长
- 9年专注AI硬件研发
- 50万+台智能设备服务全球家庭
- 德国红点奖、CE、FCC、RoHS等国际认可
- 每年研发投入占比25%——持续加大在AI基础技术上的投入
- 98.7%的用户满意度
携手前行:共同创造智能教育未来
小狮不仅是一家AI研发公司,更是一个连接技术创新与教育需求的桥梁。我们期待:
- 与教育工作者合作,让AI技术更好地服务教学
- 与家长用户沟通,让产品更贴近真实需求
- 与行业伙伴携手,共同推进AI教育生态建设
加入我们,一起探索AI的无限可能
2015年来,我们见证了AI技术从实验室走向千家万户的历程。未来,小狮将继续:
深入研发:在多模态大模型、ASR+LLM+TTS等前沿领域持续投入
拓展场景:让AI硬件覆盖更多学习场景和年龄段
开放合作:与全球合作伙伴共建AI教育生态
小狮将继续坚持“硬科技+人性化” 的双轮驱动策略,持续加大研发投入,深化多模态AI硬件的创新应用,拓展AI技术惠及更多生活场景。
深圳超乎科技有限公司和小狮(深圳)智能有限公司拥有完善“小狮”商标体系。
-
小狮AI旗舰智能手表X2产品参数与技术规格
2026年世界移动通信大会(MWC 2026)于3月2日在西班牙巴塞罗那Fira Gran Via会展中心举行,小狮AI旗舰手表X2重磅发布,大放光彩,凭借前沿 AI 技术与创新设计惊艳全场。亚非欧热销,解锁AI智能穿戴新高度。下面是小狮X2手表的详细参数:
小狮AI旗舰智能手表X2详细参数 产品尺寸 dimension 长length 50.5 mmX宽46 mmX高14.5mm 外壳尺寸有少许公差 重量 weight 67g 操作系统、处理器、内存特性Operating system, processor, memory characteristics 操作系统The operating system Android 9.0 处理器类型Processor type W527旗舰芯片 CPU:1A75@2.0GHz3A55@ 1.8GHz
CPU最高主频:2.0GHz
核数:4
制程工艺:12nm超微高集成3D SiP技术 电源管理PMU 支持 WIFI+蓝牙 WIFI:2.4G/5G 802.11b/g/n/ac 5G WiFi;BT: V4.2 /蓝牙5.0&BLE双模 存储Memory 533 MHz LPDDR3 eMCP: 4G+32G\4G+64G 定位 支持 GPS / Glonass / 北斗,支持WIFI2.4G ,支持BT SIM卡 支持 Nano SIM卡 显示屏display 2.13寸 AMOLED屏分辨率:410*502 电池 battery 1380MAH 聚合锂电池 触摸TOUCH PANEL 支持 support 指纹 指纹解锁,指纹触摸 GSM GSM: B3,B5,B8 WCDMA WCDMA:B1,B5,B8 FDD-LTE ,TDD-LTE FDD-LTE:B1,B3,B7,B8,B20(欧亚)
TDD-LTE:B34 B38,B39,B40,B41功能特性Features 天线 Antenna LDS天线 喇叭 Receiver 独立听筒 /扬声器 二合一 马达 支持 表盘自定义 支持 MIC 焊线MIC Welding line MIC 无线技术 WIFI 支持 support NFC 支持 support 无源NFC标签 蓝牙bluetooth BT 4.2 low energy /5.0 支持蓝牙耳机 手电筒 Torch 支持 support 计步 支持 support 心率传感器 支持 support 3605 血氧传感 支持 support 3605 视频格式(支持高清1080P)VIDO DECODE 支持 support 音频格式Audio formats MP3/AAC/AAC+/WMA/DRA/AMR-NB 图片格式Image format JPG, JPEG, BMP 视频解码格式 Video formats 1920×1080 @30fps;(H.264/MPEG4)编解码;支持格式 MPEG4 Encoder,H.264 Encoder,MPEG4 Decoder,H.263 Decoder,VP8 Decoder,H.264 Decoder, 电池类型The battery type LI-ON 1100MAH 聚合物锂电池 电源适配器The power adapter 输入:AC100-240V.50-60HZ, 输出: USB 5V 1A 外置 I/O 端口External I/O port USB接口 USB jack Pogo PIN 4pin USB SIM卡 单卡NANO SIM电话卡 心率 支持,同一个BTB连接器拓展 IO接口 接器拓展,功能为数据、充电、下载、、SIM卡支持气压和智能健康管理、开机键 侧键Sidekey 电源键 POWER 返回键 功耗 工作时间 2-3天 待机时间 5-7天 充电时间 3H 通话时间 连续通话时长约7小时 实际使用时间,与当地的网络信号强度有关 内置应用软件支持Buildin APP Software support 时钟Clock 支持 support 主界面Launch 支持 support 中间层Frameworks 支持 support(右滑退出当前界面) 主动运动记录(徒步,跑步,骑行,登山,游泳) 支持 support 短信SMS 支持 support 电话Phone 支持 support 通讯录Contacts 支持 support 设置Setting 支持 support 计步Step 支持 support 计算器Calculator 支持 support 浏览器Browser 支持 support 录音机AudioRecord 支持 support 日历Calendar 支持 support 电子邮件E-Mail 支持 support 搜索Search 支持 support 视频Video 支持 support 图库Gallery 支持 support 下载Download 支持 support 音乐Music 支持 support 闹钟Alarm 支持 support 心率Heartrate 支持 support 天气 支持 support 应用市场 支持 support OTA在线升级 支持 support 输入法inputmethod 支持 support 第3方应用: 微信,支付宝,QQ等 支持 support 外观颜色/认证Appearance color/certification 认证certification 3C认证、电信设备进网许可证、无线电发射设备核准证 颜色color 金色/黑色 产品亮点 AI智享 智能双ISP视频通话:前后双摄同步,守护儿童安全
智能单麦智能降噪:通话纯净,噪音无扰
智能视频防抖:高品质视频效果,画面更稳定成人模式儿童模式切换,SOS报警,后台家长监管,上课禁用,课程表,电子围栏,拦截陌生人来电,指纹识别,指纹触摸滑动功能,180度旋转抽拉摄像头,超大容量电池,应用市场自由下载,第三方应用自由禁用设置,微信支付,支付宝支付,省电模式设置,快捷菜单自由编辑。 
小狮2026旗舰智能手表四核5G全网通大模型安卓AI手表 
小狮2026旗舰智能手表四核5G全网通大模型安卓AI手表 -
小狮AI旗舰智能手表X1产品参数与技术规格
2026年世界移动通信大会(MWC 2026)于3月2日在西班牙巴塞罗那Fira Gran Via会展中心举行,小狮AI旗舰手表X1重磅发布,大放光彩,凭借前沿 AI 技术与创新设计惊艳全场。亚非欧热销,解锁AI智能穿戴新高度。下面是小狮X1手表的详细参数:
小狮AI旗舰智能手表X1详细参数 产品尺寸 dimension 长length 50.5 mmX宽46 mmX高14.5mm 外壳尺寸有少许公差 重量 weight 67g 操作系统、处理器、内存特性Operating system, processor, memory characteristics 操作系统The operating system Android 9.0 处理器类型Processor type W377E高端芯片 IMG8300 @ 800MHz 4*A53 @ 1.4GHz Mali T820 MP1 @ 384MHz 电源管理PMU 支持 WIFI+蓝牙 WIFI:2.4G 802.11b\g\n BT: V4.2 / wifi/蓝牙5.0 存储Memory 533 MHz LPDDR3 eMCP: 2G+16G\3G+32G 定位 支持 GPS / Glonass / 北斗,支持WIFI2.4G ,支持BT SIM卡 支持 Nano SIM卡 显示屏display 2.13寸 AMOLED屏分辨率:410*502 电池 battery 1380MAH 聚合锂电池 触摸TOUCH PANEL 支持 support 指纹 指纹解锁,指纹触摸 GSM GSM: B3,B5,B8 WCDMA WCDMA:B1,B5,B8 FDD-LTE ,TDD-LTE FDD-LTE:B1,B3,B7,B8,B20(欧亚)
TDD-LTE:B34 B38,B39,B40,B41功能特性Features 天线 Antenna LDS天线 喇叭 Receiver 独立听筒 /扬声器 二合一 马达 支持 表盘自定义 支持 MIC 焊线MIC Welding line MIC 无线技术 WIFI 支持 support NFC 支持 support 无源NFC标签 蓝牙bluetooth BT 4.2 low energy /5.0 支持蓝牙耳机 手电筒 Torch 支持 support 计步 支持 support 心率传感器 支持 support 3605 血氧传感 支持 support 3605 视频格式(支持高清1080P)VIDO DECODE 支持 support 音频格式Audio formats MP3/AAC/AAC+/WMA/DRA/AMR-NB 图片格式Image format JPG, JPEG, BMP 视频解码格式 Video formats 1920×1080 @30fps;(H.264/MPEG4)编解码;支持格式 MPEG4 Encoder,H.264 Encoder,MPEG4 Decoder,H.263 Decoder,VP8 Decoder,H.264 Decoder, 电池类型The battery type LI-ON 1100MAH 聚合物锂电池 电源适配器The power adapter 输入:AC100-240V.50-60HZ, 输出: USB 5V 1A 外置 I/O 端口External I/O port USB接口 USB jack Pogo PIN 4pin USB SIM卡 单卡NANO SIM电话卡 心率 支持,同一个BTB连接器拓展 IO接口 接器拓展,功能为数据、充电、下载、、SIM卡支持气压和智能健康管理、开机键 侧键Sidekey 电源键 POWER 返回键 功耗 工作时间 2-3天 待机时间 5-7天 充电时间 3H 通话时间 连续通话时长约7小时 实际使用时间,与当地的网络信号强度有关 内置应用软件支持Buildin APP Software support 时钟Clock 支持 support 主界面Launch 支持 support 中间层Frameworks 支持 support(右滑退出当前界面) 主动运动记录(徒步,跑步,骑行,登山,游泳) 支持 support 短信SMS 支持 support 电话Phone 支持 support 通讯录Contacts 支持 support 设置Setting 支持 support 计步Step 支持 support 计算器Calculator 支持 support 浏览器Browser 支持 support 录音机AudioRecord 支持 support 日历Calendar 支持 support 电子邮件E-Mail 支持 support 搜索Search 支持 support 视频Video 支持 support 图库Gallery 支持 support 下载Download 支持 support 音乐Music 支持 support 闹钟Alarm 支持 support 心率Heartrate 支持 support 天气 支持 support 应用市场 支持 support OTA在线升级 支持 support 输入法inputmethod 支持 support 第3方应用: 微信,支付宝,QQ等 支持 support 外观颜色/认证Appearance color/certification 认证certification 3C认证、电信设备进网许可证、无线电发射设备核准证 颜色color 金色/黑色 产品亮点:成人模式儿童模式切换,SOS报警,后台家长监管,上课禁用,课程表,电子围栏,拦截陌生人来电,指纹识别,指纹触摸滑动功能,180度旋转抽拉摄像头,超大容量电池,应用市场自由下载,第三方应用自由禁用设置,微信支付,支付宝支付,省电模式设置,快捷菜单自由编辑。 小狮2026旗舰智能手表四核5G全网通大模型安卓AI手表 小狮2026旗舰智能手表四核5G全网通大模型安卓AI手表 -
AI产品大发展:端侧芯片+小模型已进入量产普惠期
曾经局限于实验室的AI消费终端,如今已走出技术象牙塔,成为电商平台随处可见的现货,更是跨境电商平台上的爆款单品。2026年,低功耗RISC-V/ARM架构SoC与NPU的结合、1B–4B参数级端侧小模型的落地,以及离线多模态交互技术的成熟,三者实现深度融合,成功将“能听、会看、懂情绪、长记忆”的全维AI能力,融入到百元级智能设备中。小狮AI以量产芯片、落地模型、爆款产品为核心依托,全面拆解智能穿戴与智能玩具的AI化发展现状,剖析行业发展的核心逻辑与未来趋势。
一、AI终端爆发:电商爆款与跨境热销,印证AI刚需价值
备受关注的AI八大产品矩阵,与跨境市场的热销品类高度契合,其中AI手表、AI翻译眼镜、AI陪伴玩偶、教育机器人四大品类稳居出货量前列,不仅在海外市场实现40%–80%的溢价,退货率更控制在3%以下,充分验证了端侧AI消费产品的市场刚需。
- 小狮AI手表:集成无创血糖检测、心电实时分析、跌倒智能报警、离线AI问诊等核心功能,凭借全面的健康监测能力,日均出货量突破万台,成为可穿戴领域的核心爆款。
- AI翻译眼镜:以29g的轻量化设计打破传统翻译设备的便携瓶颈,支持45种语种离线同传与实时字幕显示,适配跨境出行、商务沟通等多元场景,跨境销量同比增幅达270%。
- AI陪伴玩具:聚焦情感交互与个性化体验,具备精准情绪识别、多轮连贯对话、长期记忆留存等能力,童声与方言识别率均超过95%,成为亲子陪伴与儿童启蒙的热门选择。
- 教育机器人:主打本地化运行模式,无需依赖云端支持,即可完成作业辅导、诗词讲解、逻辑思维训练等功能,兼顾实用性与便捷性,深受家长与学生青睐。
端侧AI之所以能推动消费市场爆发,核心驱动力在于其“零延迟、低流量、高隐私、低成本”的四大优势,彻底解决了传统云端交互模式下存在的卡顿、隐私泄露、流量成本过高三大痛点,为AI消费终端的普及奠定了基础。
小狮2026旗舰智能手表四核5G全网通大模型安卓AI手表 二、芯片底座:低功耗NPU成标配,RISC-V领跑中低端市场
智能穿戴与智能玩具的AI化落地,离不开底层硬件的支撑,专用低功耗SoC+NPU的组合已成为行业标配,芯片性能也从最初的“勉强能跑”,升级为如今的“跑得稳、跑得省”,彻底打破了AI终端普及的硬件瓶颈。结合市场价位,芯片应用可分为三个梯队:
(一)旗舰可穿戴梯队(300–800元)
- 恒玄6nm AI SoC:主要应用于高端AI眼镜,NPU算力可达1–3TOPS,支持离线语音交互与视觉感知双重能力,续航时长超过7天,不仅为Meta Ray-Ban等国际品牌供货,也是华强北高端同款产品的核心芯片选择。
- 全志/晶晨7nm方案:聚焦AI手表领域,是中高端手表的主力芯片方案,集成心电、血糖算法加速模块,可实现健康数据的本地实时分析,无需回传云端,既保障隐私又提升响应速度。
(二)主流穿戴/玩具梯队(100–300元)
- 瑞芯微RK1808/RV1126:NPU算力维持在0.5–2TOPS,可满足语音唤醒、基础图像识别等核心需求,海外爆款AI宠物玩具Ropet便采用该芯片平台,凭借高性价比实现规模化出货。
- 星宸/展锐W527:采用A57+A55架构,定位AI手表旗舰芯片,支持本地大模型推理,可流畅运行多轮对话,兼顾性能与功耗,成为中端智能穿戴的核心配置。
(三)百元入门梯队(<100元)
- 乐鑫ESP32-C3/M3(RISC-V架构):配置512KB RAM+4MB Flash,功耗低于10mW,单颗成本不足2美元,可流畅运行0.3B–1B参数的端侧小模型,能够支撑离线语音交互与简单指令响应,是百元级AI终端的核心芯片。
- 中科蓝讯/博通集成BK7258:专注于音频AI领域,集成降噪、语音唤醒、语义理解三大功能,无需额外搭配其他模块,是AI玩具、入门级智能耳机的主流芯片方案,性价比突出。
综上,芯片已不再是AI消费终端普及的瓶颈,NPU+低功耗的组合成为行业标配,其中RISC-V架构凭借成本低、能效高的优势,成功主导普惠级AI终端市场,推动AI能力下沉至百元价位。
三、端侧大模型:1B–4B参数落地,离线全功能实现突破
2026年,端侧大模型通过蒸馏、量化、垂直领域裁剪等技术优化,与芯片实现深度耦合,彻底摆脱了“体积大、功耗高、依赖云端”的困境,实现“小身材、全能力”的突破,1B–4B参数级别的端侧小模型成为消费级市场的主流选择,离线全功能运行成为核心竞争力。
(一)消费级落地模型规格
- 字节云雀Tiny/百度豆包Mini:参数范围在1B–3B之间,采用INT4/2bit量化技术,内存占用控制在128MB以内,可离线实现对话交互、知识问答、情绪识别等核心功能,适配各类轻量化AI终端。
- 阿里云通义千问Tiny:推出多模态端侧版本,专门适配AI眼镜、智能玩具等设备,支持“看+听+说”一体化交互,语音响应速度低于500ms,实现无延迟交互体验。
- DeepSeek端侧版:成为华强北AI机器人的标配模型,支持长期记忆留存、自定义人设设置,能够实现自然连贯的多轮对话,避免对话冷场,提升用户交互体验。
- 谷歌Gemma 2B/Phi-3-mini:聚焦海外玩具市场,具备完善的多语种支持能力,童声识别率超过95%,适配海外儿童玩具的交互需求,成为海外爆款玩具的核心模型选择。
(二)芯片与大模型融合量产实例(可直接复现)
- AI翻译眼镜:恒玄6nm SoC与阿里云通义千问Tiny深度适配,实现45语种离线同传,交互延迟低于800ms,存储占用控制在64MB以内,兼顾便携性与实用性。
- AI健康手表:星宸W527芯片搭配百度豆包Mini模型,可实现本地心电数据解读、个性化健康建议推送,所有数据均在本地存储,不联网也能正常使用,保障用户隐私。
- AI陪伴玩偶:乐鑫ESP32-C3芯片与字节云雀Tiny模型结合,实现离线语音唤醒、情绪识别、多轮对话等功能,芯片与模型的成本增量不足5美元,适合规模化量产。
- 教育机器人:瑞芯微RK1808芯片搭配星火小模型,可本地完成作业辅导、诗词讲解等功能,无需依赖网络,适配家庭、校园等无网场景,实用性突出。
(三)已量产验证的能力边界
- 语音能力:支持离线语音唤醒,方言、童声识别精准,降噪率达到90%以上,可在复杂环境下实现清晰交互。
- 交互能力:可实现多轮连贯对话,具备上下文记忆功能,支持个性化人设定制,交互体验更贴近人类沟通习惯。
- 视觉能力:具备物体识别、场景理解、拍照问答等功能,适配AI眼镜、机器人等带视觉模块的设备,拓展交互场景。
- 功耗能力:设备可实现7×24小时待机,连续交互续航时长超过8小时,满足日常使用需求,无需频繁充电。
回溯2025年,端侧大模型的发展已完成关键转型,从最初的“高度依赖云端”,逐步走向“端云协同”,甚至实现“纯端侧运行”,为2026年的规模化普及奠定了技术基础。这一转型的背后,离不开三大核心支撑:
- 模型压缩技术成熟:通过INT4/INT8等量化技术,大幅缩小大模型体积,降低硬件运行压力。例如智谱AI GLM-Edge-V-2B模型,以20亿参数实现每秒70tokens的端侧推理速度,彻底打破了“高性能必须高算力”的行业魔咒。
- 端侧推理芯片崛起:后摩智能M50芯片表现突出,实现160TOPS@INT8的物理算力,典型功耗仅10W,可支撑PC、机器人等终端高效运行1.5B到70B参数的本地大模型,推动高端AI终端落地。
- 国产替代加速推进:在华强北展团中,海思AI互动玩具芯片方案、逐高电子国产MCU方案集中亮相,充分展现了国产IC的创新实力,进一步夯实了智能终端底层硬件的自主可控基础。
四、产业格局:整合供应链,中国方案主导全球市场
当前,AI消费终端行业已形成清晰的产业分层,深圳凭借强大的供应链整合能力,成为全球AI可穿戴与智能玩具产业的核心枢纽,中国方案凭借性价比与技术优势,主导全球市场格局,具体分层如下:
- 芯片层:呈现“国产主导中低端、外资占据高端”的格局,乐鑫、瑞芯微、全志、恒玄等国产企业主导中低端市场,高通、三星等国际品牌占据高端市场,同时RISC-V架构快速渗透各价位段,成为产业发展新趋势。
- 模型层:国内外科技企业协同发力,字节、阿里、百度等国内企业,与谷歌等国际企业,均推出适配消费终端的轻量化端侧模型,支持7天快速移植,大幅缩短产品研发周期。
- 方案层:深圳模组厂商发挥供应链优势,提供“芯片+模型+算法”一体化解决方案,无需企业单独研发,30天即可实现产品量产,大幅降低AI终端的准入门槛。
- 品牌层:跨境品牌依托中国供应链优势,抢占全球市场份额,目前中国供应链已占据全球AI智能穿戴与智能玩具70%以上的产能,成为全球产业的核心供给端。
行业核心逻辑已发生转变:端侧AI已从最初的“技术简单堆叠”,进入芯片—模型—场景深度耦合的新阶段,随着硬件成本持续下探至普惠区间,AI消费终端的大规模普及已无技术与成本瓶颈。
五、未来趋势判断:AI消费终端进入普及爆发期
结合当前产业发展现状与技术迭代趋势,未来AI智能穿戴与智能玩具行业将呈现四大发展方向,逐步实现从“尝鲜”到“普及”的跨越:
- 硬件层面:NPU将成为智能穿戴、智能玩具的标配组件,无AI加速功能的产品将逐步被市场淘汰,低功耗、高算力的芯片将成为行业竞争的核心焦点。
- 模型层面:1B–4B参数的端侧小模型将成为市场主流,“离线优先、端云协同”的模式将成为标配,模型的个性化、场景化适配能力将进一步提升。
- 市场层面:小狮AI+跨境的模式将持续领跑全球,中国供应链将进一步巩固核心地位,逐步定义全球AI消费终端的行业标准,推动中国方案走向世界。
- 技术层面:多模态交互(听+看+触)、情感感知、长期记忆将成为产品核心卖点,AI终端将从“工具型”向“陪伴型”“服务型”转型,进一步贴近用户需求。
本质而言,智能穿戴与智能玩具的AI化,是端侧算力提升与轻量化模型成熟的共振结果。如今,芯片已实现低功耗与高算力的平衡,模型已达成小体积与强能力的统一,二者的深度融合,让AI技术真正从云端走向用户的手腕、口袋与枕边。2026年,不仅是AI消费终端从尝鲜到普及的元年,更是中国半导体与端侧模型产业,以普惠姿态抢占全球市场、树立行业标杆的起点。
从更细分的层面来看,芯片领域已形成完整的产品梯队:乐鑫、博通集成主攻低端走量市场,瑞芯微、全志聚焦中端体验提升,联发科、地平线则布局高端性能领域,全方位覆盖不同价位、不同需求的市场;技术层面,端侧大模型通过量化压缩与异构计算技术,已能在百元级MCU上实现流畅的语音交互,在千元级SoC上完成多模态识别,技术门槛持续降低;趋势层面,AI硬件已彻底摆脱“阉割版智能音箱”的标签,升级为“可移动、可交互、可感知”的边缘计算终端,芯片与模型的深度融合,正在重塑消费电子的用户体验,开启AI消费普及的新时代。
-
如何把小狮AI智能手表开发成一个智能体?
小狮 AI 智能手表从单纯的硬件,升级改造成一个能主动感知、决策、执行任务的智能体(AI Agent),核心是让手表从 “被动响应指令” 变成 “主动理解场景、自主完成任务”,而非仅做简单的语音问答。
一、核心思路:给手表装上 “智能体大脑”
智能体的核心是「感知 – 规划 – 执行 – 反馈」闭环,针对小狮 AI 手表的硬件特性(屏幕小、续航有限、有定位 / 语音 / 传感器),我们需要围绕 “轻量化、场景化、低功耗” 来设计,整体分为 4 个关键步骤:
1. 先明确手表智能体的核心场景(聚焦刚需,避免复杂)
小狮 AI 手表主要用户是儿童 / 青少年,核心场景优先选:
- 安全场景:自动识别危险(如长时间停留陌生区域、摔倒),主动给家长发预警;
- 生活场景:根据时间 / 位置主动提醒(如放学该回家、该写作业、该喝水);
- 交互场景:不用孩子喊,主动问(如 “到学校了吗?需要给妈妈报平安吗?”)。
2. 技术架构:手表端 + 云端协同(轻量化为主)
小狮手表硬件算力有限,不能把所有智能体逻辑放本地,采用 “端云结合” 方案:
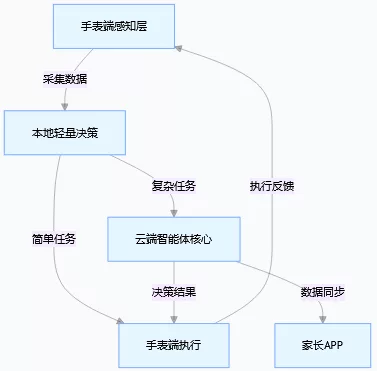
小狮AI智能手表智能体的逻辑图 3. 具体开发步骤(可落地,从简单到复杂)
步骤 1:手表端感知层改造(采集核心数据)
首先让手表能自动采集智能体需要的基础数据,基于小狮手表的 SDK / 开放接口开发:
python
# 示例:小狮手表端数据采集代码(伪代码,需适配手表系统) import time import location import sensor import voice # 1. 采集定位数据(每5分钟一次,低功耗) def get_location(): try: loc = location.get_current() # 调用手表定位接口 return {"lat": loc.latitude, "lng": loc.longitude, "time": time.time()} except Exception as e: return {"error": "定位失败", "msg": str(e)} # 2. 采集运动传感器数据(识别摔倒/异常动作) def get_sensor_data(): accel = sensor.get_accelerometer() # 加速度传感器 if abs(accel.x) > 15 or abs(accel.y) > 15: # 摔倒阈值 return {"status": "fall", "data": accel} return {"status": "normal", "data": accel} # 3. 采集环境/时间数据 def get_context_data(): return { "time": time.localtime(), "battery": sensor.get_battery(), # 电量 "network": sensor.get_network() # 网络状态 } # 4. 数据定时上报(低功耗模式) def report_data(): while True: data = { "location": get_location(), "sensor": get_sensor_data(), "context": get_context_data() } # 本地缓存+定时上报云端 upload_to_cloud(data) time.sleep(300) # 5分钟一次,避免耗电 if __name__ == "__main__": report_data()- 关键说明:手表端代码要极简,只做数据采集 + 本地极简单判断(如电量低于 10% 就不上报),避免占用算力和电量;
- 前置条件:需要拿到小狮手表的开发者权限 / SDK,或通过第三方插件方式接入。
步骤 2:云端智能体核心逻辑开发(决策 + 规划)
云端是智能体的 “大脑”,负责接收手表数据、分析场景、生成执行指令,用 Python/Java 开发,核心逻辑:
python
# 示例:云端智能体核心代码(伪代码) import json import time from geopy.distance import distance # 计算距离 # 1. 预设规则库(家长可配置) RULES = { "safe_area": {"lat": 30.1234, "lng": 120.1234, "radius": 500}, # 家的安全区域(500米) "reminder_time": {"home": "17:00", "homework": "19:00"}, # 提醒时间 "fall_alert": True # 摔倒预警开启 } # 2. 场景识别(核心:判断当前该做什么) def scene_recognize(watch_data): scene = "normal" # 场景1:超出安全区域 loc = watch_data["location"] if "lat" in loc: safe_loc = (RULES["safe_area"]["lat"], RULES["safe_area"]["lng"]) current_loc = (loc["lat"], loc["lng"]) dist = distance(safe_loc, current_loc).meters if dist > RULES["safe_area"]["radius"] and time.localtime().tm_hour > 18: scene = "out_of_safe_area" # 场景2:检测到摔倒 if watch_data["sensor"]["status"] == "fall": scene = "fall_detected" # 场景3:到提醒时间 current_hour = watch_data["context"]["time"].tm_hour current_min = watch_data["context"]["time"].tm_min if f"{current_hour}:{current_min}" == RULES["reminder_time"]["home"]: scene = "remind_go_home" return scene # 3. 执行规划(根据场景生成指令) def action_plan(scene): actions = [] if scene == "out_of_safe_area": actions = [ {"type": "watch_voice", "content": "你现在不在家附近,该回家啦!"}, {"type": "send_to_parent", "content": "孩子当前位置超出安全区域,请注意!"}, {"type": "watch_vibration", "duration": 5} ] elif scene == "fall_detected": actions = [ {"type": "watch_voice", "content": "检测到你摔倒了,需要联系家长吗?"}, {"type": "send_to_parent", "content": "紧急!孩子可能摔倒,立即查看!"}, {"type": "call_parent", "number": "138xxxx8888"} ] elif scene == "remind_go_home": actions = [ {"type": "watch_voice", "content": "放学啦,快回家吧~"}, {"type": "watch_display", "content": "该回家啦!"} ] return actions # 4. 接收手表数据,执行智能体逻辑 def ai_agent_core(watch_data): # 步骤1:识别场景 scene = scene_recognize(watch_data) # 步骤2:生成执行计划 actions = action_plan(scene) # 步骤3:下发指令给手表/家长APP for action in actions: send_action_to_device(action) # 步骤4:反馈执行结果 return {"scene": scene, "actions": actions, "status": "success"} if __name__ == "__main__": # 模拟接收手表数据 watch_data = json.loads(receive_watch_data()) result = ai_agent_core(watch_data) print(result)- 关键说明:云端逻辑核心是「规则 + 简单 AI」,先从固定规则入手(如时间 / 位置规则),后期可接入 LLM(如讯飞星火、文心一言)提升场景理解能力;
- 依赖:需要搭建云端服务器(如阿里云 / 腾讯云轻量服务器),实现手表 – 云端 – 家长 APP 的通信。
步骤 3:手表端执行层改造(响应云端指令)
手表端接收云端的智能体指令,执行语音、震动、显示等操作:
python
# 示例:手表端执行指令代码(伪代码) def execute_action(action): try: if action["type"] == "watch_voice": voice.play(action["content"]) # 播放语音提醒 elif action["type"] == "watch_vibration": sensor.vibrate(duration=action["duration"]) # 震动 elif action["type"] == "watch_display": screen.show(action["content"]) # 屏幕显示 return {"status": "executed"} except Exception as e: return {"status": "failed", "error": str(e)} # 监听云端指令 def listen_cloud(): while True: action = receive_from_cloud() # 接收云端指令 if action: execute_action(action) time.sleep(10) # 每10秒监听一次步骤 4:反馈闭环(智能体自我优化)
让智能体记住执行结果,逐步优化:
- 记录 “提醒孩子回家” 后,孩子是否按提醒行动(通过定位变化判断);
- 家长可在 APP 里标记 “预警是否准确”,云端根据反馈调整规则(如安全区域半径、提醒时间)。
二、开发注意事项(适配小狮手表特性)
- 功耗控制:手表电池小,数据采集 / 上报频率不能太高(定位 5 分钟一次,传感器 1 分钟一次),优先用低功耗模式;
- 网络适配:手表多为 2G/4G 物联网卡,数据传输要压缩(只传关键字段,不用 JSON 全量);
- 权限合规:儿童数据要符合隐私法规(如 GDPR、未成年人保护法),数据加密存储,不泄露位置 / 语音;
- 简化交互:手表屏幕小、语音识别有限,智能体指令要简单(语音提醒≤10 秒,显示文字≤1 行)。
-
小狮AI多模态大模型与硬件开发四阶段课程体系
第一阶段 筑基篇:AI与嵌入式开发基础(4个月)
阶段目标:建立扎实编程基础,掌握数据处理和机器学习核心概念
完整学习内容:
- Python编程全面掌握
- Python基础语法:变量、数据类型、运算符、流程控制
- 核心数据结构:列表、元组、字典、集合、字符串操作
- 函数编程:参数传递、作用域、lambda表达式、装饰器
- 面向对象编程:类与对象、继承、多态、封装、特殊方法
- 异常处理:try-except-finally、自定义异常、异常链
- 文件操作:文本文件、二进制文件、CSV/JSON处理
- 模块与包:import机制、标准库常用模块、pip包管理
- 并发编程:多线程、多进程基础、异步编程概念
- 开发环境与工程基础
- Linux基础:常用命令、文件权限、进程管理、Shell脚本编写
- Git版本控制:commit/branch/merge/rebase、GitHub/GitLab协作
- 虚拟环境:venv/conda环境管理、依赖文件(requirements.txt)
- Docker基础:镜像与容器、Dockerfile编写、容器化部署
- 编辑器熟练:VSCode/PyCharm配置、调试器使用、代码格式化
- AI数学基础(以应用为导向)
- 线性代数:向量、矩阵运算、张量概念(理解神经网络数据流动)
- 概率与统计:条件概率、贝叶斯思想、正态分布(理解模型不确定性与评价指标)
- 微积分基础:导数、梯度(理解模型优化的核心)
- 数据处理核心技能
- NumPy深度学习:数组创建、索引切片、广播机制、矩阵运算
- Pandas全面掌握:Series/DataFrame、数据清洗、分组聚合、时间序列
- 数据可视化:Matplotlib基础绘图、Seaborn统计图表、Plotly交互图表
- 数学基础:线性代数(矩阵、向量、特征值)、概率统计(分布、假设检验)
- 硬件开发初体验
- 硬件平台入门:认识树莓派/Jetson Nano等典型AI硬件,完成系统烧录、网络配置、SSH远程登录
- 嵌入式编程Hello World:在硬件上用Python控制一个LED灯或读取一个按钮信号,理解硬件交互的基本逻辑
- 机器学习基础实战
- 监督学习算法:线性回归、逻辑回归、决策树、随机森林、SVM、KNN
- 无监督学习:K-means聚类、层次聚类、DBSCAN、PCA降维
- 模型评估:准确率/精确率/召回率/F1、ROC曲线、交叉验证
- Scikit-learn全流程:数据预处理、特征工程、管道(Pipeline)、网格搜索
第二阶段 融合篇:深度学习与多模态基础(6个月)
阶段目标:掌握深度学习核心原理,建立NLP和CV基础能力
完整学习内容:
- 深度学习框架深入
- PyTorch/TensorFlow二选一精通:张量操作、自动求导、模型定义、训练循环
- 神经网络基础:全连接层、激活函数、损失函数、优化器
- GPU编程:CUDA基础、设备管理、并行计算优化
- 自定义模块:Layer设计、Model封装、checkpoint保存
- 计算机视觉核心技术
- 图像处理基础:OpenCV图像读写、色彩空间、滤波变换
- CNN架构:LeNet、AlexNet、VGG、ResNet、DenseNet原理与实现
- 目标检测:R-CNN系列、YOLO系列、SSD原理与代码实现
- 图像分割:FCN、U-Net、Mask R-CNN、实例分割
- 图像生成:GAN基础、DCGAN、StyleGAN原理
- 自然语言处理核心技术
- 文本预处理:分词、词干提取、停用词过滤、文本向量化
- 词嵌入技术:Word2Vec(CBOW/Skip-gram)、GloVe、FastText
- RNN系列:简单RNN、LSTM、GRU、双向RNN、序列到序列
- Transformer基础:自注意力机制、位置编码、编码器-解码器结构
- BERT预训练:掩码语言模型、下一句预测、Fine-tuning策略
- 多模态模型入门与应用
- 多模态数据表示:特征提取、对齐方法、融合策略
- 视觉-语言模型:学习CLIP(图文匹配)、BLIP(图文生成)的原理与API调用
- 多模态理解:学习如何将图像、语音特征与文本对齐,输入给LLM
- 语音模型:学习Whisper(语音识别)的调用与简单微调。
- 模型服务化基础
- 云端API开发:使用FastAPI构建简单的模型推理API服务。
- 硬件端模型轻量化启蒙:了解ONNX格式、TensorRT或TFLite的基本概念,知晓这是端侧部署的桥梁。
- 大模型架构深入
- Transformer高级主题:多头注意力、前馈网络、层归一化
- 模型缩放:参数规模、数据规模、计算规模对性能影响
- 注意力变体:稀疏注意力、线性注意力、分块注意力
- 位置编码:绝对位置、相对位置、旋转位置编码
- 开源大模型实战
- Llama系列:模型架构、分词器、微调方法(LoRA/QLoRA)
- ChatGLM系列:对话格式、推理优化、多轮对话管理
- Qwen系列:视觉语言模型、多模态能力、工具调用
- 视觉语言模型:BLIP-2、MiniGPT-4、LLaVA架构与训练
- 模型优化与部署
- 模型量化:INT8量化、FP16混合精度、量化感知训练
- 模型压缩:剪枝技术、知识蒸馏、低秩分解
- 推理优化:算子融合、内核优化、批处理策略
- 服务化部署:FastAPI/Flask服务编写、并发处理、负载均衡
- 推理框架:ONNX Runtime、TensorRT、OpenVINO优化
- 多模态对话系统
- 提示工程:few-shot prompting、chain-of-thought、role-playing
- 对话管理:状态跟踪、上下文管理、历史信息维护
- 工具调用:函数调用规范、工具选择、结果整合
- 评估方法:人工评估、自动评估指标、A/B测试设计
- 系统集成:API设计、错误处理、限流降级策略
- 云端服务架构
- 后端服务开发:使用Python(Flask/Django)构建稳健的云端服务端,用于接收硬件数据、调度AI模型
- 任务队列与异步处理:使用Celery + Redis处理耗时的模型推理请求,实现请求异步化
- 云API集成:在云端服务中集成大语言模型API(如GPT-5)、语音识别API、多模态理解API
- 对话状态管理:设计简单的基于规则或模型的对话状态机,管理用户会话上下文
- 上下文管理:学习在云端如何维护和存储多轮对话的上下文信息,并有效地输入给LLM
- 嵌入式Linux系统:Buildroot/Yocto系统定制、内核配置、驱动开发
- 交叉编译环境:GCC交叉编译工具链、CMake跨平台编译
- 边缘推理框架:TensorFlow Lite完整应用、PyTorch Mobile部署
- 模型优化技术:量化工具使用、算子支持、模型转换
- 硬件性能分析:性能计数器、功耗测量、热管理
- 资源约束编程:内存池管理、CPU亲和性、实时性保障
- 主流硬件平台:树莓派全系列开发、NVIDIA Jetson系列开发
- 硬件接口编程:GPIO数字IO、I2C/SPI/UART串行通信、PWM控制
- AI加速器编程:NVIDIA TensorRT、Intel OpenVINO、华为Ascend CL
- 传感器集成:麦克风阵列配置、摄像头驱动、环境传感器、用Python/C++控制硬件
- 硬件抽象层:设备驱动接口、统一设备管理、错误恢复
- 实时系统:RTOS基础、中断处理、优先级调度
- 音频硬件:麦克风选型、声学设计、ADC参数配置
- 信号处理:采样定理、傅里叶变换、滤波器设计
- 语音前端:硬件端音频的降噪、语音活动检测(VAD)、回声消除、噪声抑制
- 音频编解码:PCM编码、Opus/AAC压缩、流媒体传输
- 云端ASR集成:百度/阿里/腾讯语音识别API、流式识别
- 语音合成:TTS API调用、音频缓存、播放同步
- 唤醒引擎:Snowboy/Picovoice定制、误唤醒控制
- 视觉采集:USB/UVC摄像头、CSI摄像头、多摄像头同步
- 视频处理:OpenCV视频捕获、帧处理、编码传输
- 传感器融合:IMU数据、温度湿度、光线传感器
- 特征提取:视觉特征、音频特征、时序特征
- 融合算法:早期融合、晚期融合、混合融合策略
- 上下文建模:场景识别、用户状态、环境感知
- 通信协议:MQTT协议栈、CoAP轻量协议、WebSocket双向通信
- 安全机制:TLS/SSL加密、设备认证、访问控制
- 设备管理:设备注册、状态上报、远程控制
- 数据同步:增量同步、冲突解决、数据一致性
- 模型更新:差分更新、版本管理、回滚机制
- 监控系统:设备状态监控、性能指标上报、告警机制
- 系统架构设计:模块划分、接口定义、数据流设计
- 启动流程:Bootloader、内核启动、应用启动顺序
- 服务管理:Systemd服务配置、进程监控、自动重启
- 存储管理:文件系统选择、日志轮转、数据备份
- OTA系统:升级包生成、校验机制、安全升级
- 对话流水线:
- 语音唤醒→端点检测→音频传输→ASR转换
- 文本理解→大模型推理→响应生成→TTS转换
- 音频播放→状态更新→历史记录
- 性能优化:延迟分析、瓶颈定位、系统调优
- 测试验证:单元测试、集成测试、压力测试、兼容性测试
- 部署流程:镜像制作、批量部署、配置管理、监控部署
- 编程语言:Python 3.9+
- 深度学习框架:PyTorch 2.0+
- 部署框架:FastAPI + Docker
- 硬件平台:树莓派4B+/Jetson Nano
- 云服务:可选阿里云/腾讯云API
第三阶段 精进篇:嵌入式AI与多模态大模型融合(6个月)
阶段目标:掌握大模型微调部署,构建多模态对话系统
完整学习内容:
第四阶段 化神篇:AI硬件集成与系统攻坚(8个月)
阶段目标:掌握边缘AI部署,实现端到端硬件产品开发,理解音频处理流水线:拾音(麦克风)-> VAD -> 网络传输 -> 云端ASR -> 云端大模型处理 -> 云端TTS -> 网络回传 -> 本地播放(扬声器)。
1. 边缘计算与嵌入式AI开发
完整技术栈:
2. AI硬件平台深度开发
完整技术栈:
3. 实时语音处理系统
完整技术栈:
4. 多模态感知融合
完整技术栈:
5. 云边协同通信架构
完整技术栈:
6. 端到端产品化实现
“端-边-云”协同架构。在树莓派或类似开发板上实现:音频采集与播放:使用PyAudio或ALSA库。语音活动检测(VAD): 使用WebRTC VAD等轻量级库,实现本地唤醒和降噪。网络通信:通过HTTP/WebSocket与云端服务稳定通信。任务调度与多线程:管理录音、发送、接收、播放等并发任务。
完整技术栈:
技术栈:
- Python编程全面掌握
-
AI学习第四阶段 化神篇:前沿探索与系统攻坚(8-12个月)
学习目标
掌握端云协同AI产品的完整开发流程,能够独立完成具备多模态对话功能的AI硬件产品开发与部署,重点实现”AI闹钟”的非离线语音对话功能。
第一部分:产品级系统架构与设计模式
使用FastAPI或Flask构建轻量级Web服务器。 设计并实现核心API:
ASR端点:接收硬件上传的音频流,调用云端ASR服务(如Whisper API或国内同等服务)转为文本。LLM端点:接收文本,调用大模型API(或本地部署的模型),生成回复文本。TTS端点:将回复文本调用云端TTS服务(如Edge-TTS、微软Azure等)转为音频流。
1.1 端云协同架构设计
- 分层架构设计:设备端-边缘网关-云端服务三层架构
- 通信模式选择:同步HTTP/HTTPS vs 异步WebSocket/MQTT
- 数据流设计:音频流、控制指令流、状态同步流的分离与整合
- 微服务架构:ASR服务、LLM服务、TTS服务、对话管理服务的解耦设计
1.2 硬件选型与平台对比
- 主流AI硬件平台深度对比:
- 树莓派5 vs Jetson Nano/Orin系列
- 瑞芯微RK3588 vs 高通QCS系列
- 地平线旭日X3 vs 华为Atlas 200
- 音频子系统选型:
- 麦克风阵列:2麦/4麦/6麦阵列的波束成形效果对比
- 音频编解码器:ADC/DAC芯片选型(ES8388, WM8960)
- 扬声器功率与音质平衡
- 功耗与散热设计:
- 不同唤醒频率下的功耗测算
- 被动散热 vs 主动散热方案
- 电源管理设计(锂电池 vs 直流供电)
1.3 安全性架构设计
- 传输安全:TLS/SSL双向认证,硬件证书存储
- 数据隐私:端侧音频预处理(本地VAD),敏感信息过滤
- 防攻击设计:DDOS防护,请求频率限制,输入验证
第二部分:硬件端嵌入式开发实战
2.1 嵌入式Linux深度定制
- 最小化系统构建:使用Buildroot或Yocto构建定制化Linux镜像
- 内核驱动开发:
- ALSA音频驱动配置与优化
- I2C/SPI总线驱动(用于外接传感器)
- GPIO中断处理(物理按键唤醒)
- 系统服务管理:systemd服务配置,开机自启管理
2.2 网络通信与状态管理
- 自适应网络连接:
- WiFi/Ethernet/4G多链路备份
- 弱网环境下的连接保持策略
- 断线重连与状态恢复机制
- 协议设计与实现:python
# 自定义二进制协议头设计 class AudioPacket: header = { 'version': 1, 'packet_type': 'audio_stream', 'timestamp': int(time.time() * 1000), 'sequence': 0, 'codec': 'pcm_16k', 'vad_status': 'speech_start' } payload: audio_data
2.3外设驱动开发与优化
- ALSA音频驱动:多声道同步、低延迟配置
- I2S音频接口:时钟同步、数据格式配置
- WiFi/BT驱动:低功耗管理、漫游优化
第三部分:端侧音频处理与唤醒引擎
- 专业级音频处理流水线
拾音 → 多通道同步 → 波束成形 → AEC回声消除 → NS降噪 → AGC增益控制 → VAD检测 → 音频编码
- WebRTC音频处理模块集成
- 深度学习降噪:RNNoise轻量级模型部署
- 3A算法参数调优:房间声学自适应
- 本地唤醒词系统
- Porcupine/Snowboy引擎深度集成
- 自定义唤醒词训练与准确率优化
- 双重唤醒确认机制:声纹辅助验证
- 音频编解码与传输优化
- 低比特率编码:Opus vs AMR-WB对比
- 丢包补偿:PLC包丢失隐藏技术
- 自适应码率:基于网络质量的动态调整
第四部分:云端多模态服务架构
- 高性能微服务设计
- gRPC/HTTP2服务通信框架
- 异步任务处理:Celery + Redis任务队列
- 连接池管理:数据库连接、模型服务连接
- 大模型服务化架构
- 模型服务化:Triton Inference Server部署
- 多模型动态加载:按需加载与卸载
- 请求批处理:动态批处理优化吞吐量
- 智能对话管理系统
- 对话状态跟踪:有限状态机 vs 深度学习策略
- 上下文管理:滑动窗口注意力机制
- 个性化适配:用户画像实时更新
- ASR/TTS服务深度集成
- ASR服务优化:
- 流式ASR vs 整句ASR的选择策略
- 领域自适应:针对闹钟场景的语音模型微调
- 实时纠错:基于对话上下文的文本纠错
- TTS个性化定制:
- 情感语音合成(开心、平静、紧急等不同语气)
- 语音克隆技术(定制化人声)
- 音效合成(闹钟铃声、提示音效)
第五部分:端云通信与协议优化
- 自定义二进制通信协议
[包头:16字节][载荷:变长][校验:4字节] 包头字段:魔数、版本、命令字、序列号、时间戳、载荷长度
- 协议设计:头部压缩、字段编码优化
- 序列化方案:Protobuf vs MessagePack对比
- 心跳与保活:自适应心跳间隔
弱网环境优化策略
- 智能重传:选择性重传SACK
- 前向纠错:FEC冗余数据添加
- 多路径传输:WiFi/蜂窝网络双通道
数据同步与状态管理
- CRDT无冲突复制数据类型应用
- 最终一致性保证
- 断网续传:断点续传协议设计
第六部分:部署、监控与全链路优化
- 大规模部署方案
- 容器化部署:Docker多架构镜像构建
- K8s编排:设备管理DaemonSet、服务部署Deployment
- 配置管理:ConfigMap热更新、Feature Flag功能开关
- 全链路监控体系
- 四大黄金指标:延迟、流量、错误、饱和度
- 分布式追踪:Jaeger/Elastic APM全链路跟踪
- 业务指标:用户满意度CSAT、任务完成率
- 性能调优方法论
- 瓶颈定位:火焰图分析、性能计数器监控
- 端到端延迟优化:关键路径分析
- A/B测试框架:实验分组、指标收集、效果分析
- OTA升级与运维
- 差分升级:bsdiff算法应用
- 灰度发布:设备分组升级策略
- 故障回滚:版本快速回退机制
